Robots : qu'est-ce c'est ?
👉 Les robots sont des applications qui exécutent des tâches automatisées sur Internet. Ils sont utilisés pour indexer le contenu ou pour recueillir automatiquement des informations sur les sites web.
Certains robots fonctionnent à des fins légitimes, tandis que d'autres collectent des données à des fins malveillantes, par exemple :
- Revente de contenu
- Génération de clics
- Prix cassés
- Etc.
Comme toute solution web basée sur les clients, Didomi est impacté par le trafic de robots qui génèrent de fausses données. Par conséquent, Didomi peut générer des analyses CMP inexactes.
Impact sur les indicateurs de la CMP
La mesure la plus touchée est le nombre total de notices (avec une augmentation du volume), qui augmente directement les indicateurs de performance comme le taux de rebond des notices et le taux d'adressabilité.
Offrir des données analytiques sans robots
👉 Les robots impactent les données Web: ils génèrent de fausses données sur les utilisateurs. Ils détériorent le taux d'adressabilité, ainsi que le taux de consentement des pages vues, tout en augmentant le volume des rebonds de notice et le nombre de pages vues sans consentement donné.
Dans ce cas, exclure les UA représente à la fois un risque de conformité et légal.
Deux types de robots se distinguent :
Les robots déclarés : ils peuvent être détectés grâce à leur agent utilisateur (ou UA). Ils sont exclus avec la méthode de filtrage par agent utilisateur. Quelques exemples de robots :
-
- Robot dits "scaper" : ils sont programmés pour capturer le contenu hors ligne, les noms, les prix et les détails des produits sur les sites de commerce en ligne.
- Les robots d'exploration : ils sont utilisés par les grandes entreprises, telles que Google, Yahoo, etc., pour indexer du contenu.
- Les robots de performance/audit : ils sont utilisés par les outils de performance des sites web pour effectuer des audits de référencement ou pour calculer les performances du temps de chargement des pages. Didomi utilise également un robot pour évaluer la conformité des sites web.
Les robots cachés : ils utilisent des agents utilisateurs standards et ne peuvent donc pas être identifiés avec la méthode de filtrage des agents utilisateurs.
Une solution/technologie spécialisée est requise pour les détecter puis pour les exclure des données analytiques.
Exemples d'agents utilisateurs
Robots déclarés
- Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) TagInspector/500.1 Chrome/90.0.4430.72 Safari/537.36 Edg/90.0.818.42
- Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/85.0.4183.102 Safari/537.36
- Mozilla/5.0 (iplabel; Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36
Eléments qui ne font pas partie d'un agent utilisateur standard.
Robots cachés
- Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36
- Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.64
Même si les agents utilisateurs ci-dessus sont utilisés par les robots, ils sont également utilisés par des visiteurs normaux : dans ce cas, les agents utilisateurs ne peuvent pas être exclus.
Attention à vos propres bots
Si vous utilisez des outils pour évaluer les performances de votre site web : comme le temps de chargement des pages, audit SEO, etc.
Ils utilisent probablement des bots pour le faire. En conséquence, ils produisent des données s'ils ne sont pas identifiés par notre solution. Vous le pouvez :
- Vérifiez les bots que nous détectons (voir la liste ci-dessous).
- Vérifiez avec vos solutions si les bots ont un modèle de UA.
- Ajoutez les modèles dans la fonction personnalisée de gestion de votre robot.
⚙️ Par défaut, (quand la case « Bots » n’est pas cochée sur la console), les robots vont “contourner” la notice de consentement. Et on considère que le consentement est déjà donné pour les robots et tous les scripts seront donc déclenchés, ainsi que les événements de consentement. La bannière ne s’affiche donc pas et ne collecte pas le consentement.
➡️ Si vous souhaitez collecter le consentement pour les bots dans votre Consent Notice, vous pouvez suivre notre article Bypass consent collection for bots.
Vous pouvez ajouter le code JSON à votre Consent Notice dans 2.Customization; Advanced settings ; Custom Json.
Gestion personnalisée des robots et contourner la collecte du consentement
👉 Vous pouvez personnaliser directement la gestion des robots avec des fichiers json personnalisés lors de votre implémentation du SDK.
Les fonctionnalités offrent les possibilités suivantes :
- Définir les catégories de robots à bloquer
- Ajouter de modèles d'agents utilisateurs (termes) à des fins d'exclusion
Retrouvez ici toutes les informations dans notre documentation technique.
Liste des robots de Didomi
👉 Plus de 90 robots sont automatiquement détectés par la CMP et lors du traitement de nettoyage des données. Vous trouverez ci-dessous la liste des modèles de robots (termes) utilisés pour identifier le trafic. Tous les visiteurs dont l'agent utilisateur contient les termes suivants sont identifiés comme des robots.
Robots d'exploration
Googlebot, adsbot, feedfetcher, mediapartners, bingbot, bingpreview, slurp, linkedin, msnbot, teoma, alexabot, exabot, facebot, facebook, twitter, yandex, baidu, duckduckbot, qwant, archive, applebot, addthis, slackbot, reddit, whatsapp, pinterest, moatbot, google-xrawler, NETVIGIE, PetalBot, PhantomJS, NativeAIBot, Cocolyzebot, SMTBot, EchoboxBot, Quora-Bot, BLP_bbot, MAZBot, ScooperBot, BublupBot, Cincraw, HeadlessChrome, diffbot, Google Web Preview, Doximity-Diffbot, Rely Bot, pingbot, cXensebot, PingdomTMS, AhrefsBot, semrush, seenaptic, netvibes, taboolabot, SimplePie, APIs-Google, Google-Read-Aloud, googleweblight, DuplexWeb-Google, Google Favicon, Storebot-Google, TagInspector, Rigor, Bazaarvoice, KlarnaBot, pageburst, naver, iplabel, des termes plus communs comme “robot”, “scraper”, “crawler”, “spider”, “crawling” et “oncrawl”.
Robots de performance
Chrome-Lighthouse, gtmetrix, speedcurve, DareBoost, PTST, StatusCake_Pagespeed_Indev.
Schéma de gestion des robots
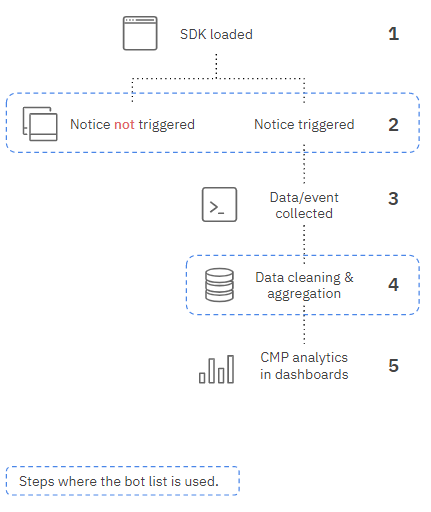
(1) Le SDK est chargé
(2) Déclenchement de la vérification des règles :
- Le SDK analyse l'agent utilisateur pour identifier s'il s'agit d'un robot ou non.
- Si un robot est détecté, le comportement de la notice est défini par la configuration (déclencher ou non la notification).
- Si le visiteur n'est pas identifié comme un robot, la notice est déclenchée.
(3) Les événements de la CMP (affichage de la notice) sont déclenchés
(4) Traitement des données (transformer les événements en analyses)
👉 Tous les événements (les données) collectés à partir de robots (identifiés) sont exclus de l'analyse, même si la notice a été affichée volontairement.
(5) Les données d'analyses sont affichées.
Outils de protection contre les robots
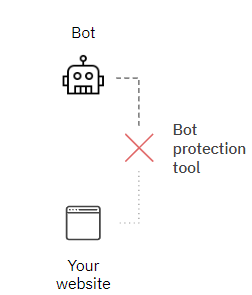
Certaines solutions sont spécialisées dans la détection et la protection des robots. Elles protègent votre site web contre leur trafic.
Ces solutions détectent les robots avant qu'ils n'atteignent le site web (voir schéma), elles peuvent empêcher le robot de charger une page et donc d'avoir un impact sur les données analytiques offertes par la CMP.
Pour plus d'informations, consultez des informations sur des solutions comme Datadome, Human, Cloudflare, Netacea, etc.